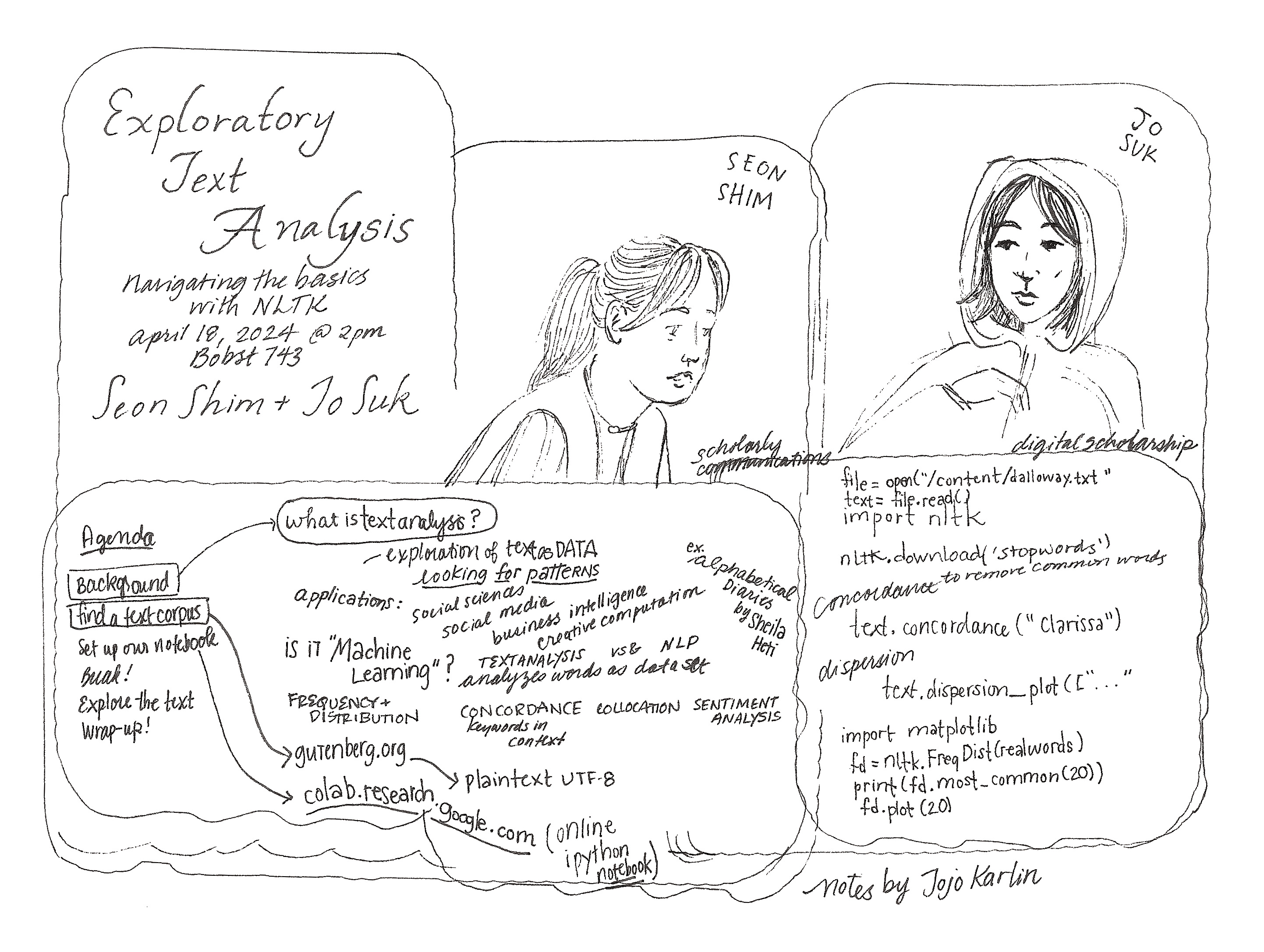
This spring, we (Seon and Jo) co-led a workshop on exploratory text analysis using the Natural Language Toolkit, or NLTK. The workshop participants included adjunct faculty, graduate students, an administrator, and one library admin/faculty member. They came with varying levels of prior experience with programming, but we mostly moved at the pace of those who were coding in Python for the first time.
We began with a brief introduction to text analysis, which we defined as the process of computationally analyzing a text as if it were a database. We spoke about the applications of text analysis across various fields, from the social sciences to business intelligence. Then we overviewed the text analysis methods that we would be covering during the tutorial portion of the workshop: frequency distribution, concordance (AKA keywords in context), and collocation.
We eased into the tutorial portion by asking participants to find and download a corpus of their choice from Project Gutenberg. Some picks included Virginia Woolf’s To the Lighthouse and Plato’s Phaedrus. Then we did some preliminary cleaning on our plain text files in order to prepare them for analysis. This entailed removing the metadata pre-injected by Project Gutenberg and making sure our text files were formatted so they could be parsed by Python.
For the remainder of the workshop, we taught the participants how to do their own text analysis using Princeton University’s CS109 Lab on NLTK as a template. NLTK is a library of prebuilt commands that facilitates our ability to analyze text using Python. To guide participants through some of the basic NLTK functions, we provided a template in the form of an interactive Python notebook (IPYNB) file and used it in Google Colab, which is an interactive web-based environment for developing and running Python code.
Participants progressed at their own pace while we troubleshot error messages one at a time. Some participants were able to help the others with bugs that they themselves had run into just a few minutes before. The resulting atmosphere was one of both collaboration and solitary exploration.
Overall, we were pleased with the pace of the lesson and happy to have provided the first few steps in our participants’ longer journeys with text analysis and perhaps even programming generally.
Above: Illustration by Jojo Karlin.